数据库存储 在爬虫写完了,添加了一个新的功能,把爬取到的数据存到了数据库中。
部分代码如下:
print ("正在写入数据库..." )engine = create_engine("mysql+mysqlconnector://root:root@localhost:3306/douban?charset=utf8" ) conn = engine.connect() df = pd.read_csv(r'douban_top250.csv' , header=None , names=head) df.sort_values('rank' , inplace=True ) df = df.replace('无' , np.NaN) df.to_sql("douban_top250" , conn, index=False , index_label='rank' ) conn.execute("""ALTER TABLE `{}` ADD PRIMARY KEY (`{}`);""" .format ('douban_top250' , 'rank' )) conn.close() print ("写入数据库成功!" )
效果:
数据可视化 (此段过程全程在jupyter notebook中完成)https://pyecharts.org/#/ https://gallery.pyecharts.org/#/
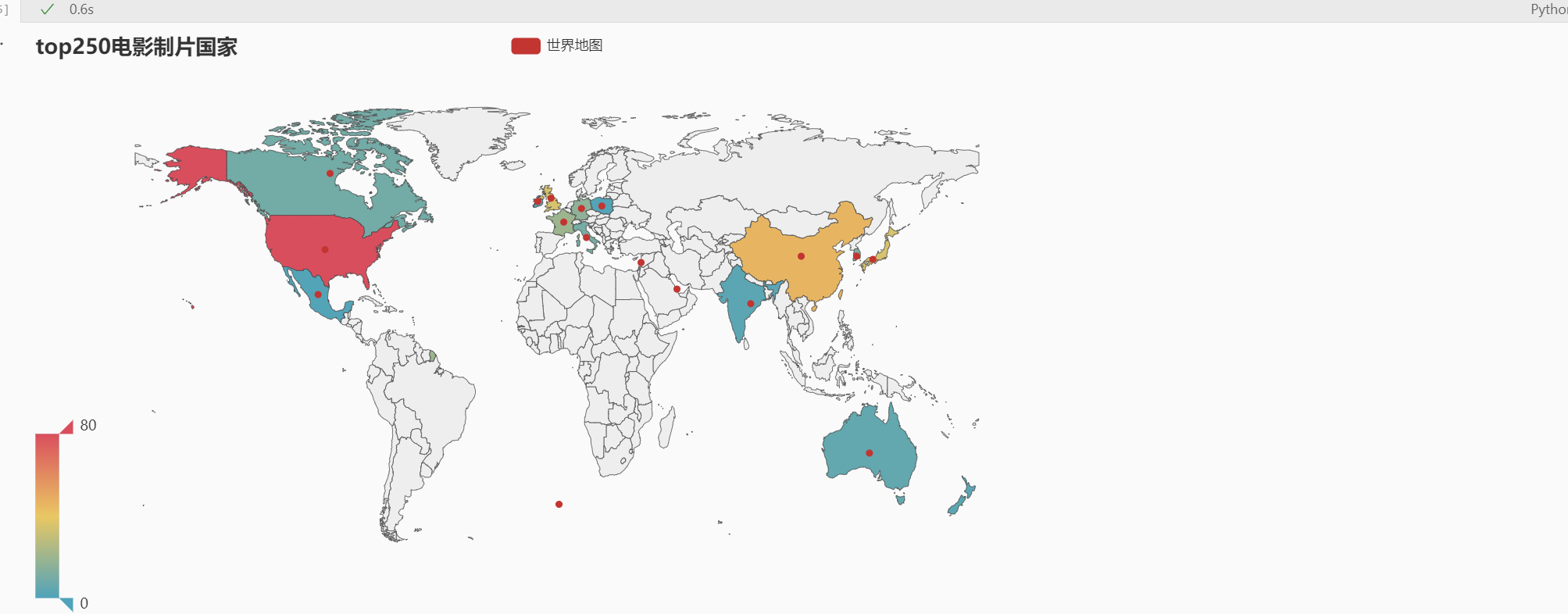
top250中的主要国家分布 Map def country (situa ): death = df['area' ].str .contains(situa) Situa = df.loc[death] return len (Situa) Country_value = [country('中国' ), country('美国' ), country('英国' ), country('法国' ), country('意大利' ), country('日本' ), \ country('新西兰' ), country('韩国' ), country('瑞士' ), country('印度' ), country('波兰' ), country('澳大利亚' ), country('墨西哥' ), \ country('卡塔尔' ), country('黎巴嫩' ), country('爱尔兰' ), country('加拿大' ), country('德国' )] Country_attr = ['China' , 'United States' , 'United Kingdom' , 'France' , 'Italy' , 'Japan' , 'New Zealand' , 'Korea' ,\ 'Swizetland' , 'India' , 'Poland' , 'Australia' , 'Mexico' , 'Qatar' , 'Lebanon' , 'Ireland' , 'Canada' , 'Germany' ] value = Country_value attr = Country_attr data = [] for index in range (len (attr)): city_ionfo=[attr[index],value[index]] data.append(city_ionfo) m = ( Map() .add("世界地图" ,data, "world" ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False )) .set_global_opts( title_opts=opts.TitleOpts(title="top250电影制片国家" ), visualmap_opts=opts.VisualMapOpts(max_=80 ), ) ) m.render_notebook()
展示:
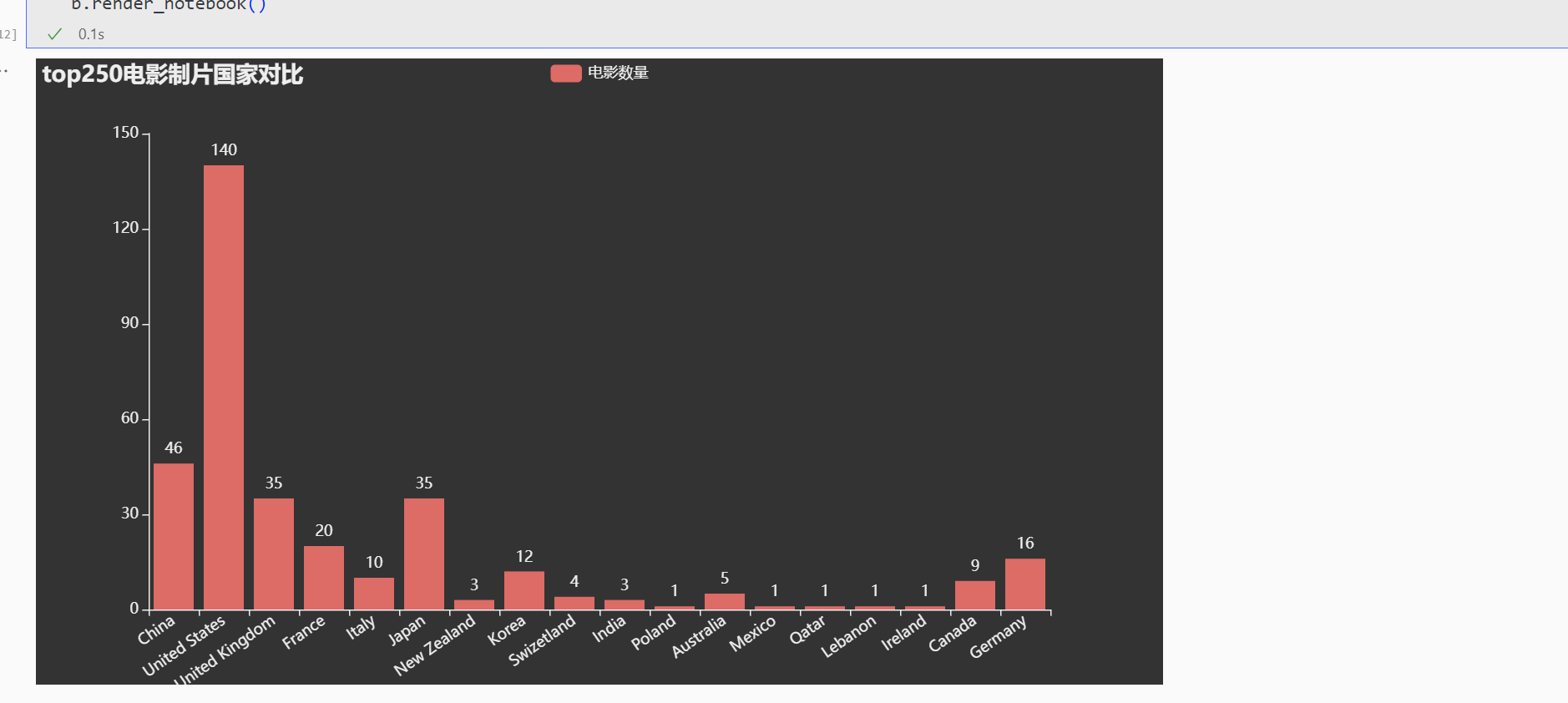
Bar x_choose=Country_attr y_values=Country_value b= ( Bar( init_opts=opts.InitOpts( theme=ThemeType.DARK, ) ) .add_xaxis(x_choose) .add_yaxis("电影数量" , y_values,) .set_global_opts( xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=35 )), title_opts=opts.TitleOpts(title="top250电影制片国家对比" ), ) ) b.render_notebook()
展示:
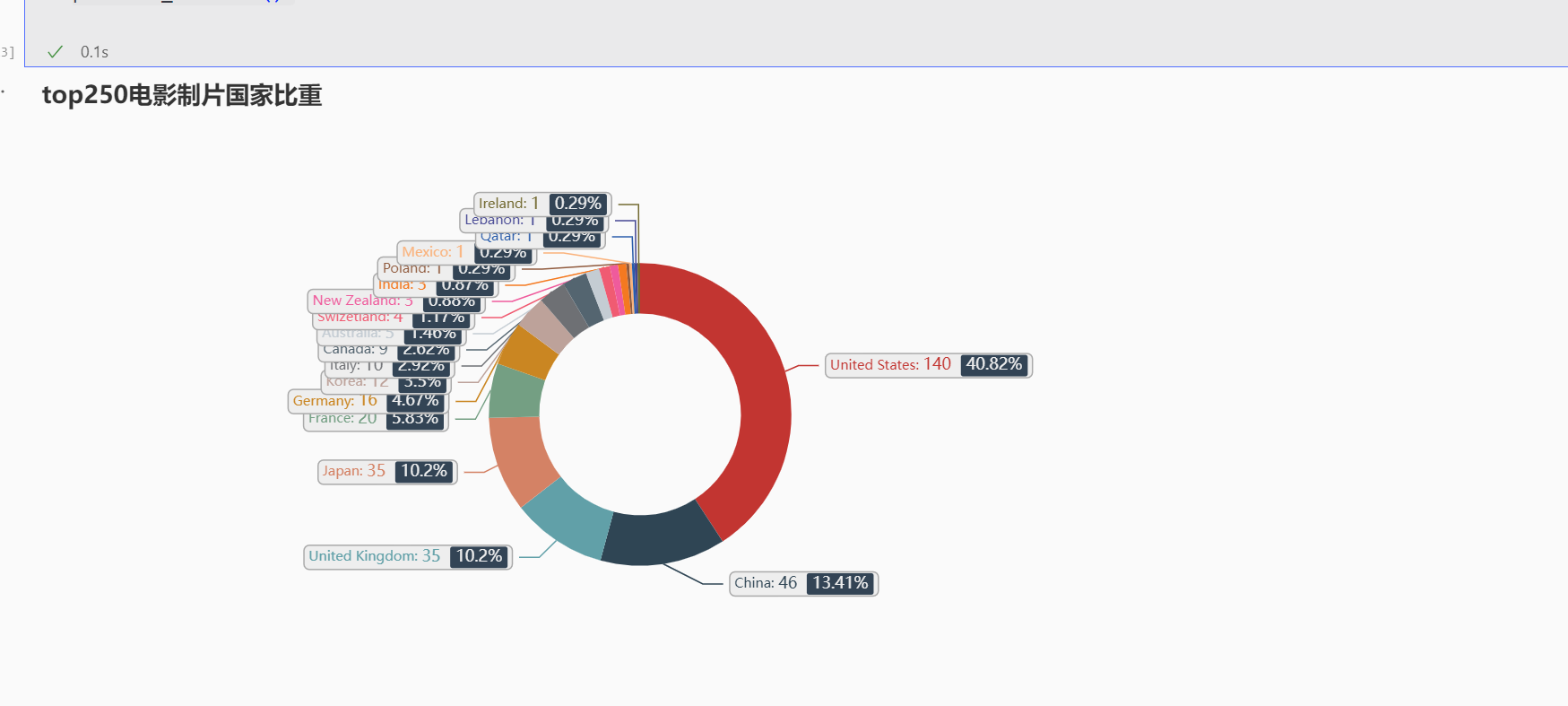
Pie # Pie - Pie_rich_label # https://gallery.pyecharts.org/#/Pie/pie_rich_label sortedData = sorted(data, key=lambda st:st[1], reverse=True) p = ( Pie() .add( "", sortedData, radius=["30%", "45%"], label_opts=opts.LabelOpts( position="outside", formatter=" {b|{b}: }{c} {per|{d}%} ", background_color="#eee", border_color="#aaa", border_width=1, border_radius=4, rich={ "a": {"color": "#999", "lineHeight": 22, "align": "center"}, "abg": { "backgroundColor": "#e3e3e3", "width": "100%", "align": "right", "height": 20, "borderRadius": [4, 4, 0, 0], }, "hr": { "borderColor": "#aaa", "width": "100%", "borderWidth": 0.5, "height": 0, }, "b": {"fontSize": 10, "lineHeight": 18}, "per": { "color": "#eee", "backgroundColor": "#334455", "padding": [2, 4], "borderRadius": 2, }, }, ), ) .set_global_opts( title_opts=opts.TitleOpts(title="top250电影制片国家比重"), legend_opts=opts.LegendOpts(is_show=False) ) ) p.render_notebook()
展示:
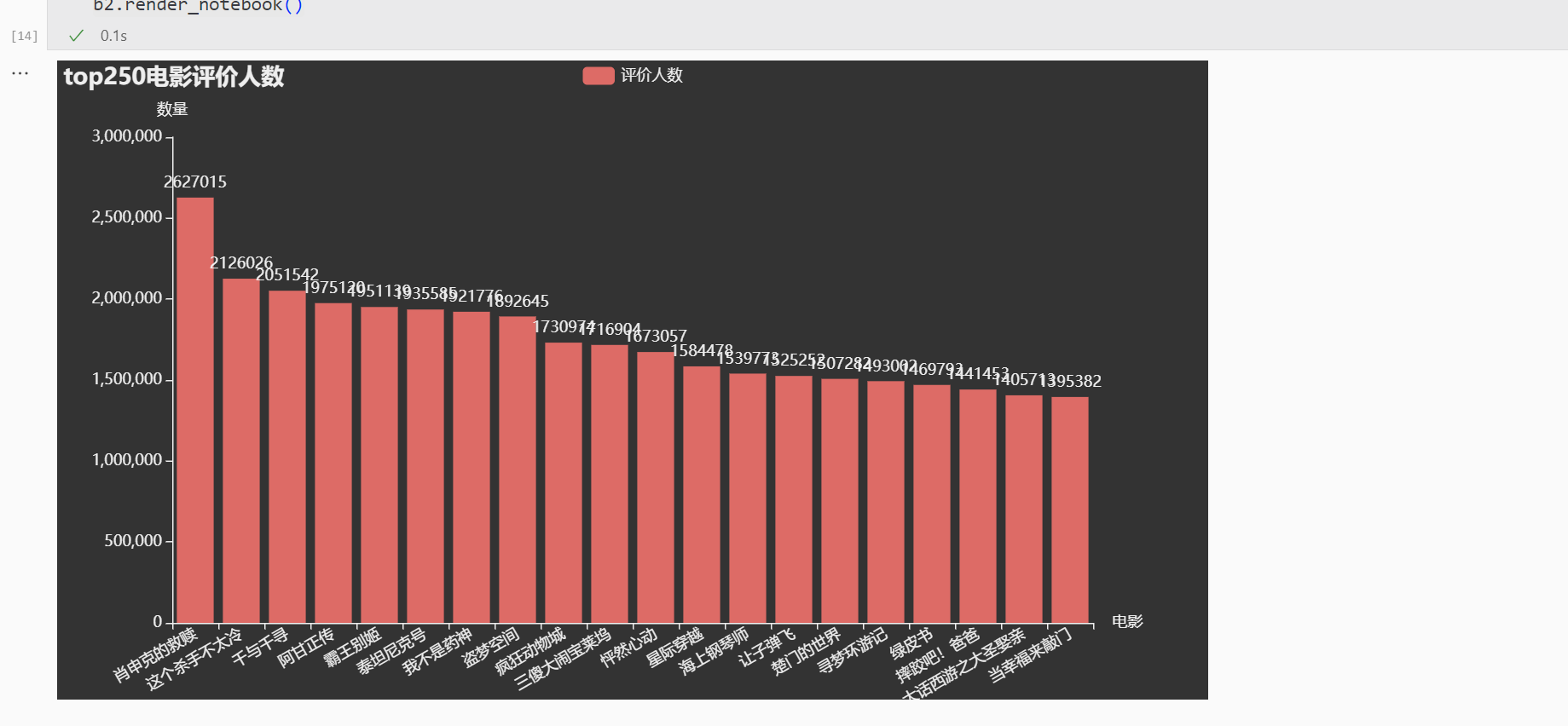
电影评价人数or电影热度 Bar2 from pyecharts.globals import ThemeTyperating_attr = [] rating_value = [] p_lists = df['rating_people' ].sort_values(ascending=False ) for i in range (20 ): rating_attr.append(df['film_name' ][p_lists.index[i]]) rating_value.append(int (p_lists[p_lists.index[i]])) x_choose=rating_attr y_values=rating_value b2= ( Bar(init_opts=opts.InitOpts( theme=ThemeType.DARK )) .add_xaxis(x_choose) .add_yaxis("评价人数" , y_values) .set_global_opts( xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30 ), name="电影" ), title_opts=opts.TitleOpts(title="top250电影评价人数" ), yaxis_opts=opts.AxisOpts(name="数量" ), ) ) b2.render_notebook()
展示:
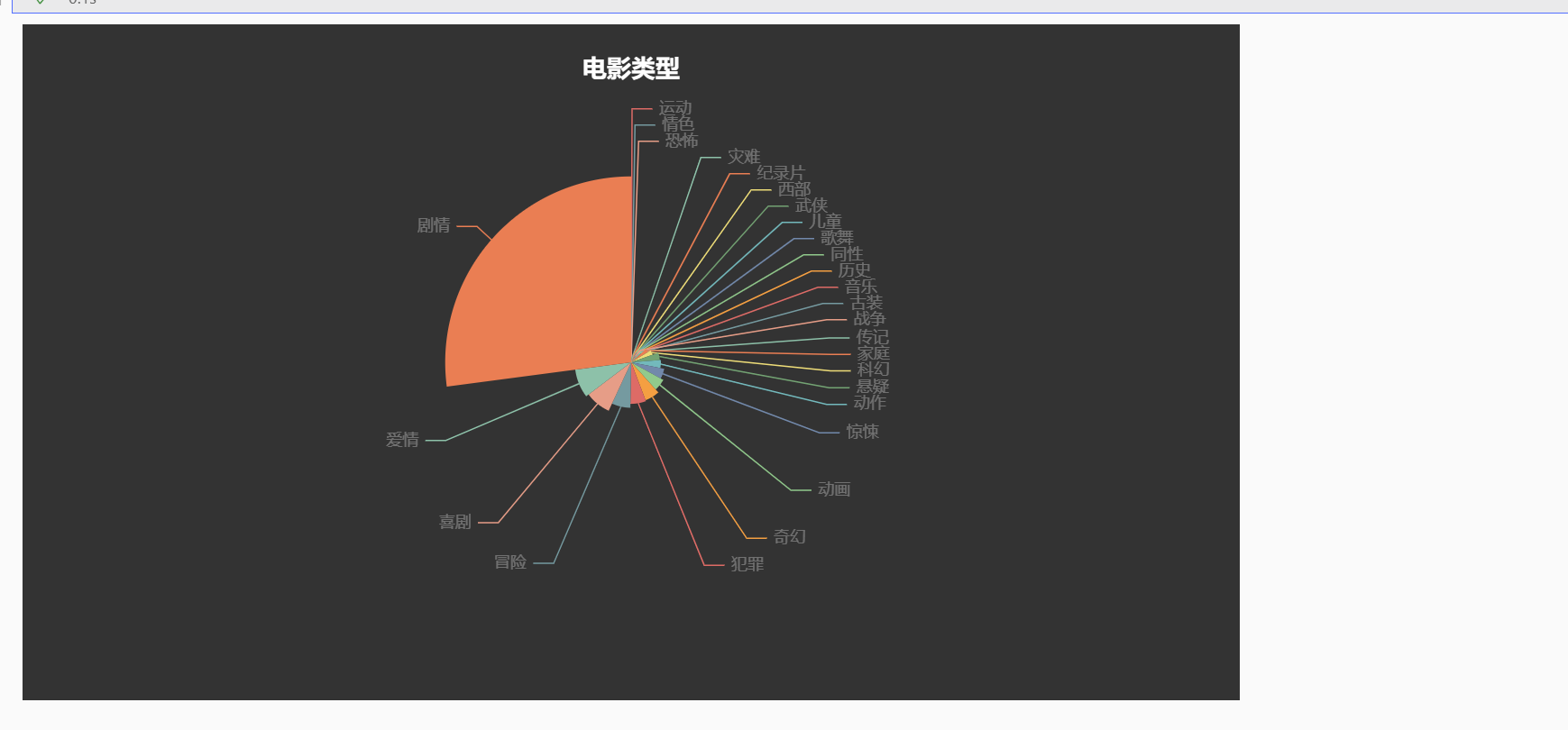
电影类型 Pie2 f_type_lists = [] for i in range (len (df['filmType' ])): for j in range (len (df['filmType' ][i].split(',' ))): f_type_lists.append(df['filmType' ][i].split(',' )[j].split("'" )[1 ].split("'" )[0 ]) f_type_lists = [x.strip() for x in f_type_lists if x.strip() != '' ] df_f_type = pd.DataFrame(f_type_lists) df_f_type.value_counts() x_f_type_data = [] y_f_type_data = [] for i in range (len (df_f_type.value_counts())): x_f_type_data.append(df_f_type.value_counts().index[i][0 ]) y_f_type_data.append(int (df_f_type.value_counts()[i])) data_pair = [list (z) for z in zip (x_f_type_data, y_f_type_data)] data_pair.sort(key=lambda x: x[1 ]) p2=( Pie( init_opts=opts.InitOpts( theme=ThemeType.DARK )) .add( series_name="类型" , data_pair=data_pair, rosetype="radius" , radius="55%" , center=["50%" , "50%" ], label_opts=opts.LabelOpts(is_show=False , position="center" ), ) .set_global_opts( title_opts=opts.TitleOpts( title="电影类型" , pos_left="center" , pos_top="20" , title_textstyle_opts=opts.TextStyleOpts(color="#fff" ), ), legend_opts=opts.LegendOpts(is_show=False ), ) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger="item" , formatter="{a} <br/>{b}: {c} ({d}%)" ), label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)" ), ) ) p2.render_notebook()
展示:
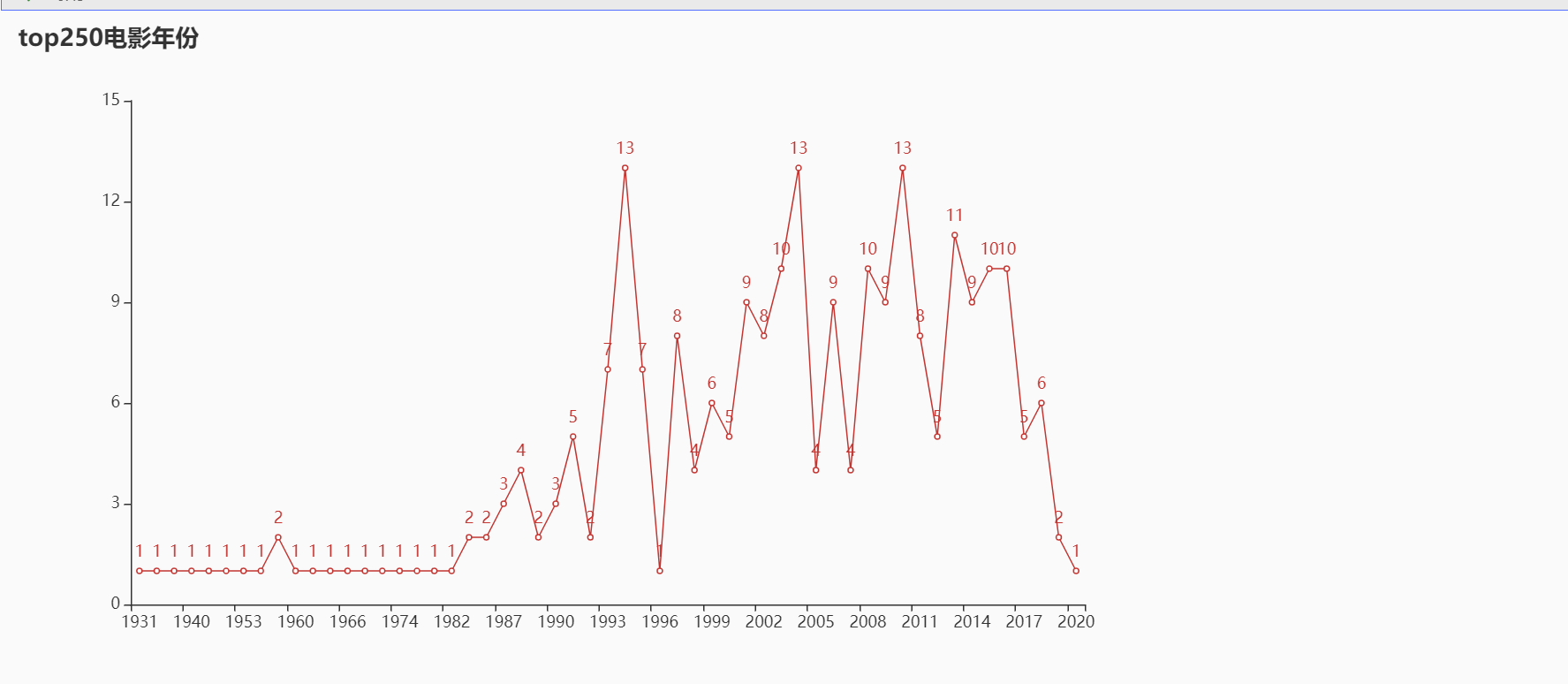
电影年份 Line releaseYear = pd.to_datetime(df['initialReleaseDate' ]) releaseYear = pd.DatetimeIndex(releaseYear).year releaseYear = releaseYear.value_counts().sort_index() xais = [] yais = [] xais = releaseYear.index.tolist() yais = releaseYear.values.tolist() for i in range (len (xais)): xais[i] = str (xais[i]) l=( Line() .add_xaxis(xaxis_data=xais) .add_yaxis( series_name="" , y_axis=yais, ) .set_global_opts( title_opts=opts.TitleOpts(title="top250电影年份" ), ) ) l.render_notebook()
展示:
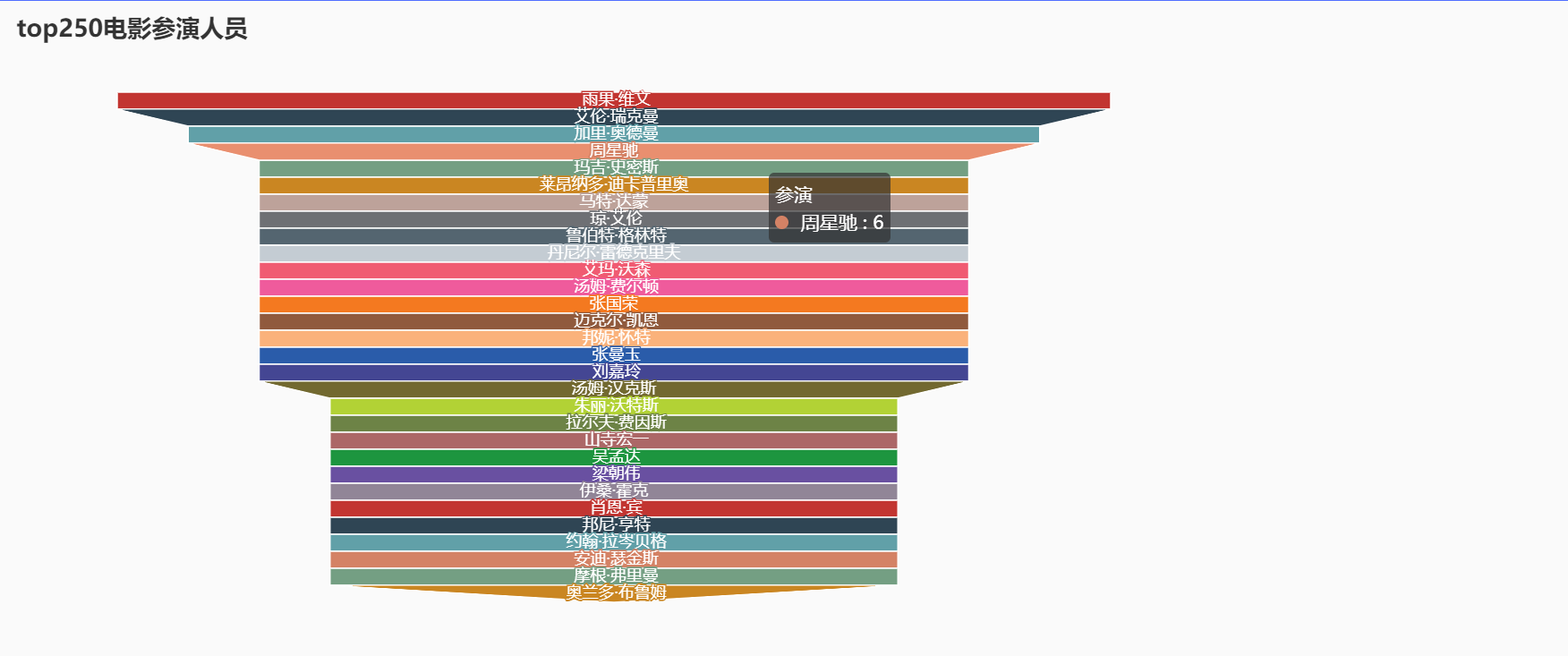
演员参演数 Funnel actors = df['actor' ] actors = pd.Series([str (line).strip('[' ).strip(']' ) for line in actors]) actors = actors.str .split(',' , expand=True ) actors_index = pd.concat([actors.loc[0 ], actors.loc[1 ]], axis=0 , ignore_index=True ) for i in range (2 , len (actors)): actors_index = pd.concat([actors_index, actors.loc[i]], axis=0 , ignore_index=True ) actors_index.dropna(inplace=True ) actors_index = actors_index.str .replace("'" , "" ) actors_sort = actors_index.value_counts().sort_values(ascending=False ) x_data = actors_sort.index.to_list() y_data = actors_sort.values.tolist() p_data = [] for index in range (30 ): p_ionfo=[x_data[index],y_data[index]] p_data.append(p_ionfo) p_data f = ( Funnel() .add( "参演" , p_data, label_opts=opts.LabelOpts(position="inside" ) ) .set_global_opts( title_opts = opts.TitleOpts(title="top250电影参演人员" ), legend_opts= opts.LegendOpts(is_show=False ) ) ) f.render_notebook()
展示:
数据分析 根据以上展示的图表,我们可以观察到美国的文化意识输出还是非常强的,对于在豆瓣上的观众来说,对美国的电影评价更改,我还发现其中有很多老电影。
数据处理与可视化技术总结 利用pyecharts进行可视化比较简单,只需要将需要的数据传给函数,就会自动渲染出图片,但是处理数据的过程就显得比较困难了。https://pandas.pydata.org/ **)

 QQ
QQ wechat
wechat alipay
alipay



