需求分析 爬虫是获取数据一种方式,能够按照一定规则自动抓取某个网站或者万维网信息的程序;现实环境中很大一部分网络访问都是由爬虫造成的;我们来看一个常见应用场景:
1.增量型爬虫:不会限制抓取数据属性,比如Google, baidu搜索引擎都是增量型爬虫;他们无时无刻不在抓取数据,还会根据一定算法评价网站的好坏,定期抓取最新数据,以保证他们的搜索结果时效性,正确性;
2.批量型爬虫:限制抓取的属性,抓取特定网站的信息;此次我们选用的方法就是批量性爬虫。
我使用Python完成批量型爬虫的设计与实现,并对抓取数据进行清洗与分析,为什么选择Python?
1.爬虫相关模块:requests、Bs4、 lxml等;
2.数据库相关模块:pyMySQL、pyMongo等;
3.数据分析相关模块:numpy,pandas,matplotlib等;
4.数据可视化模块:pyecharts
基于这些模块,快速的构建爬虫,抓取数据,并且对抓取的数据进行分析及可视化。
需求:
环境搭建 开发环境: python3.9, edge浏览器
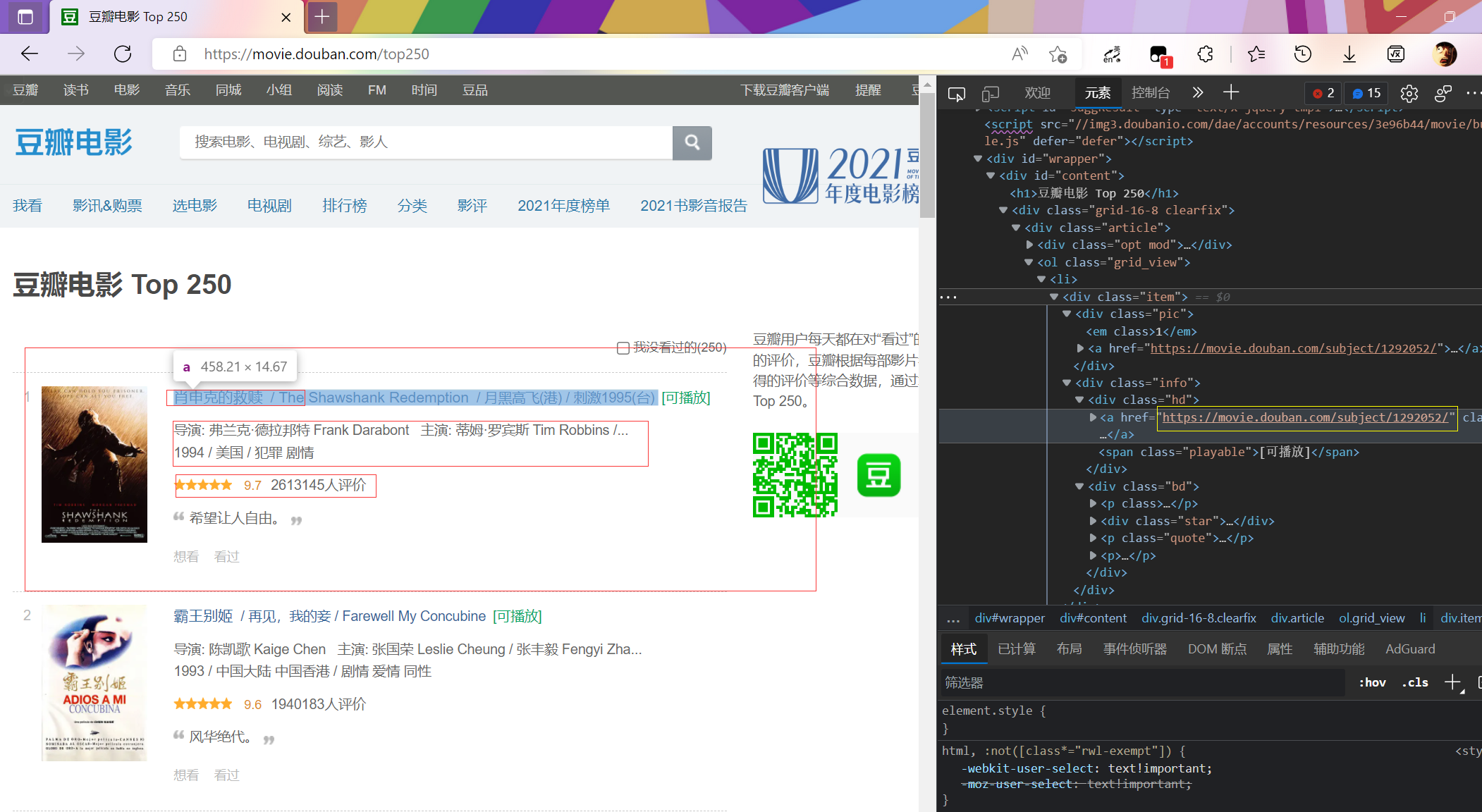
数据爬取 1. 准备工作 url: https://movie.douban.com/top250
import requestsfrom lxml import etreeimport randomimport timeheaders = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39 " } url = 'https://movie.douban.com/top250?start=0&filter=' resp = requests.get(url, headers=headers) resp.encoding = "utf-8" html = etree.HTML(resp.text) lis = html.xpath("/html/body/div[3]/div[1]/div/div[1]/ol/li" ) page_url = [] for li in lis: page = li.xpath("./div/div[2]/div[1]/a/@href" )[0 ] page_url.append(page) print (page_url)
输出结果
['https://movie.douban.com/subject/1292052/', 'https://movie.douban.com/subject/1291546/', 'https://movie.douban.com/subject/1292720/', 'https://movie.douban.com/subject/1292722/', 'https://movie.douban.com/subject/1295644/', 'https://movie.douban.com/subject/1292063/', 'https://movie.douban.com/subject/1291561/', 'https://movie.douban.com/subject/1295124/', 'https://movie.douban.com/subject/3541415/', 'https://movie.douban.com/subject/3011091/', 'https://movie.douban.com/subject/1889243/', 'https://movie.douban.com/subject/1292064/', 'https://movie.douban.com/subject/1292001/', 'https://movie.douban.com/subject/3793023/', 'https://movie.douban.com/subject/2131459/', 'https://movie.douban.com/subject/1291549/', 'https://movie.douban.com/subject/1307914/', 'https://movie.douban.com/subject/25662329/', 'https://movie.douban.com/subject/1292213/', 'https://movie.douban.com/subject/5912992/', 'https://movie.douban.com/subject/1296141/', 'https://movie.douban.com/subject/1291841/', 'https://movie.douban.com/subject/1849031/', 'https://movie.douban.com/subject/6786002/', 'https://movie.douban.com/subject/3319755/'] 进程已结束,退出代码0
可以看到我们只获得了一部分
page_url = [] def one_page (url ): resp = requests.get(url, headers=headers) resp.encoding = "utf-8" html = etree.HTML(resp.text) lis = html.xpath("/html/body/div[3]/div[1]/div/div[1]/ol/li" ) for li in lis: page = li.xpath("./div/div[2]/div[1]/a/@href" )[0 ] page_url.append(page) resp.close() if __name__ == '__main__' : for i in range (10 ): one_page(f"https://movie.douban.com/top250?start={i * 25 } &filter=" ) time.sleep(random.randint(1 , 3 )) print (page_url)
输出:
['https://movie.douban.com/subject/1292052/', ......, 'https://movie.douban.com/subject/2297265/'] (链接过多此处省略) 进程已结束,退出代码0
可以看到所以子页面url都爬取出来了
2.子页面信息提取 子页面分析
为了方便后面采用的是jupyter实时输出方便修改代码。
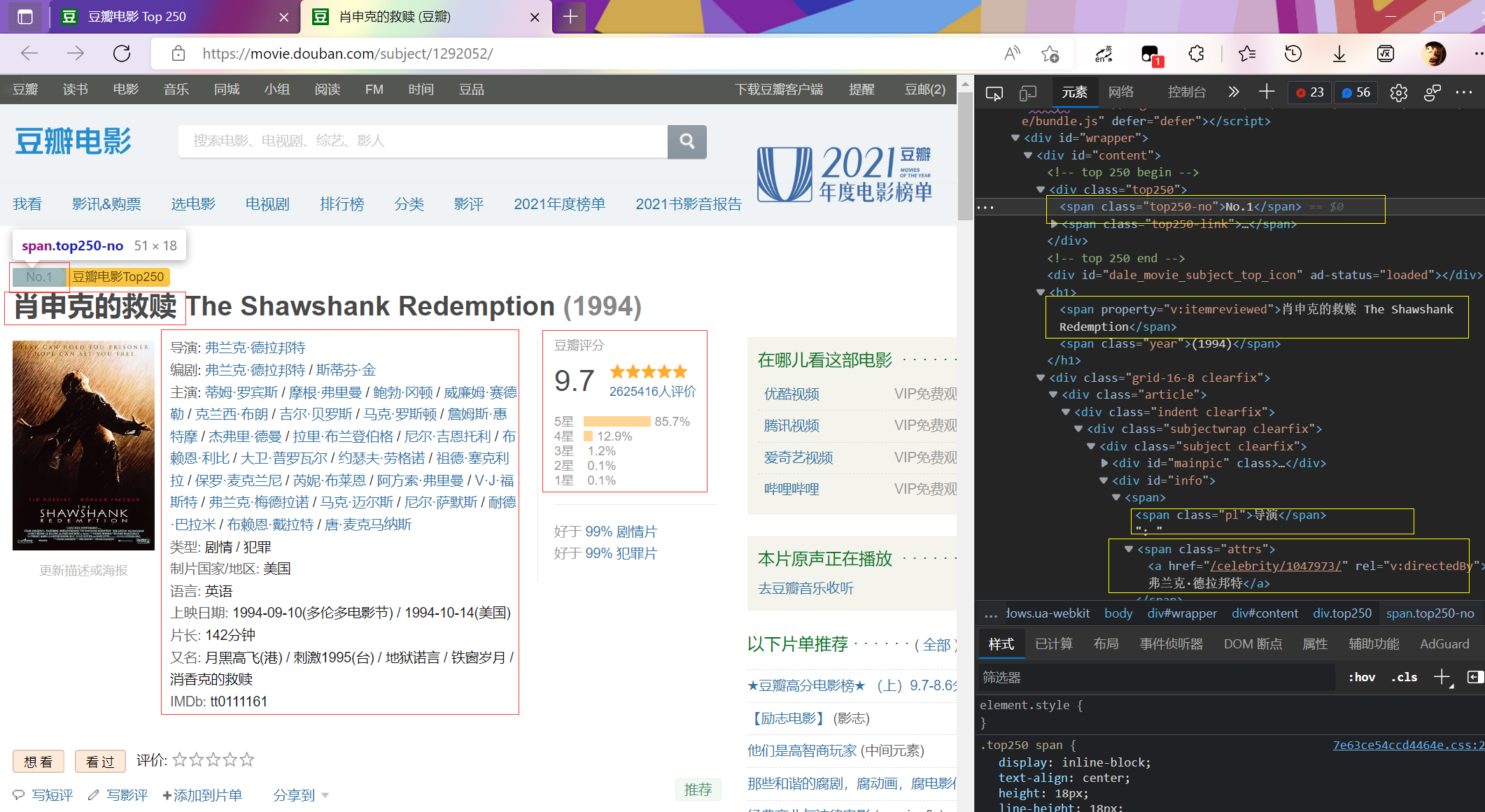
from bs4 import BeautifulSoupfrom lxml import etree import pandas as pdimport numpy as npfilm_url='https://movie.douban.com/subject/1292052/' request =requests.get(film_url,headers=headers,timeout=10 ) request.encoding = 'utf-8' film_info=[] child_page=BeautifulSoup(request.text,'html.parser' ) rank = child_page.find(attrs={'class' : 'top250-no' }).text.split('.' )[1 ] film_name = child_page.find(attrs={'property' : 'v:itemreviewed' }).text.split(' ' )[0 ] director = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[1 ].split(':' )[1 ].split('/' ) scriptwriter = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[2 ].split(':' )[1 ].split('/' ) actor = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[3 ].split(':' )[1 ].split('/' ) filmtype = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[4 ].split(':' )[1 ].split('/' ) area = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[5 ].split(':' )[1 ].split('/' ) language = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[6 ].split(':' )[1 ].split('/' ) initialReleaseDate = min (child_page.find(attrs={'id' : 'info' }).text.split('\n' )[7 ].split(':' )[1 ].split('/' )).split('(' )[0 ] runtime = child_page.find(attrs={'property' : 'v:runtime' }).text rating_num = child_page.find(attrs={'property' : 'v:average' }).text stars5_rating_per = child_page.find(attrs={'class' : 'rating_per' }).text rating_people = child_page.find(attrs={'property' : 'v:votes' }).text film_info=[rank,film_name,director,scriptwriter,actor,filmtype,area,language,initialReleaseDate,runtime,rating_num,stars5_rating_per,rating_people] print (film_info)request.close() df = pd.DataFrame([film_info]) df
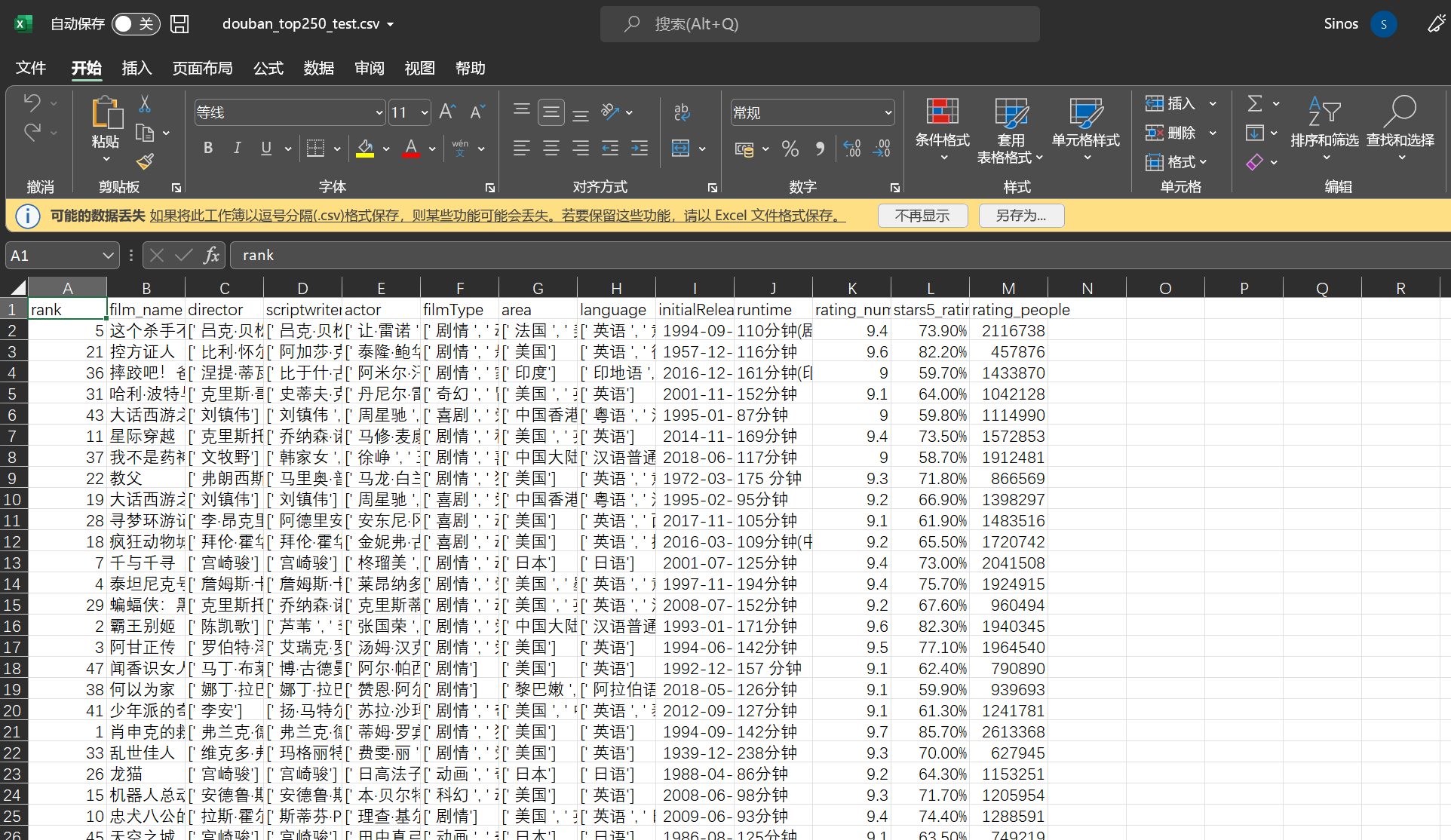
输出
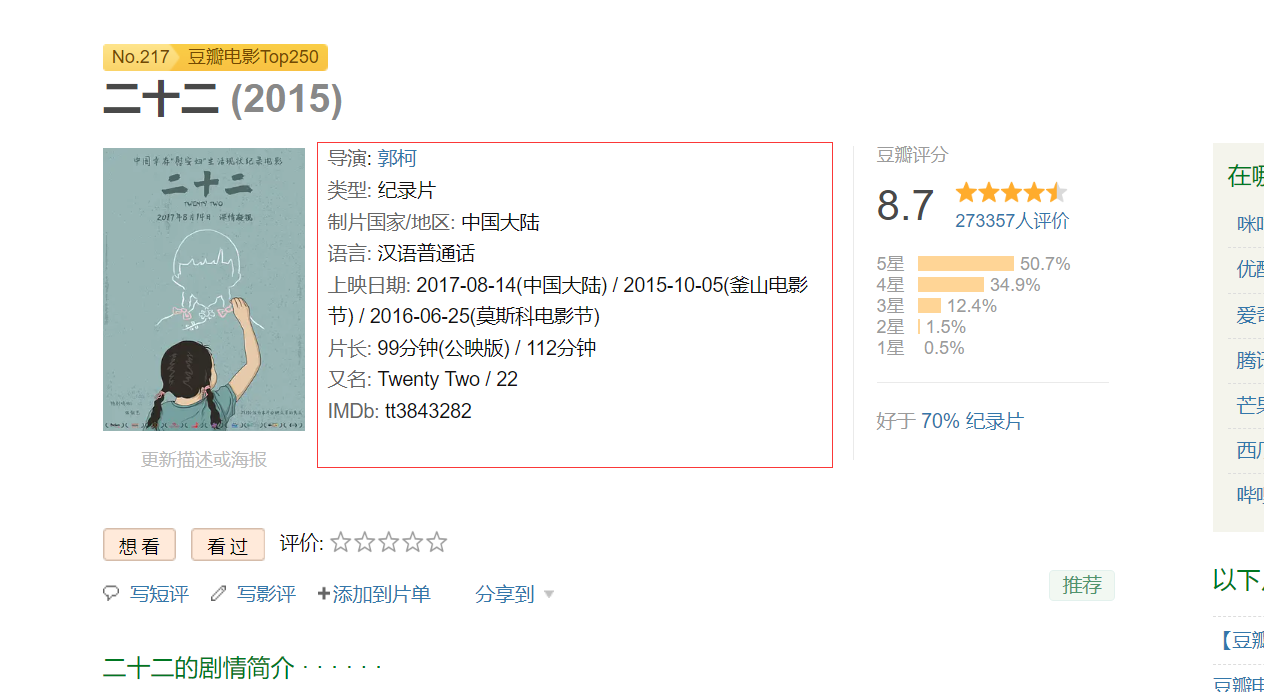
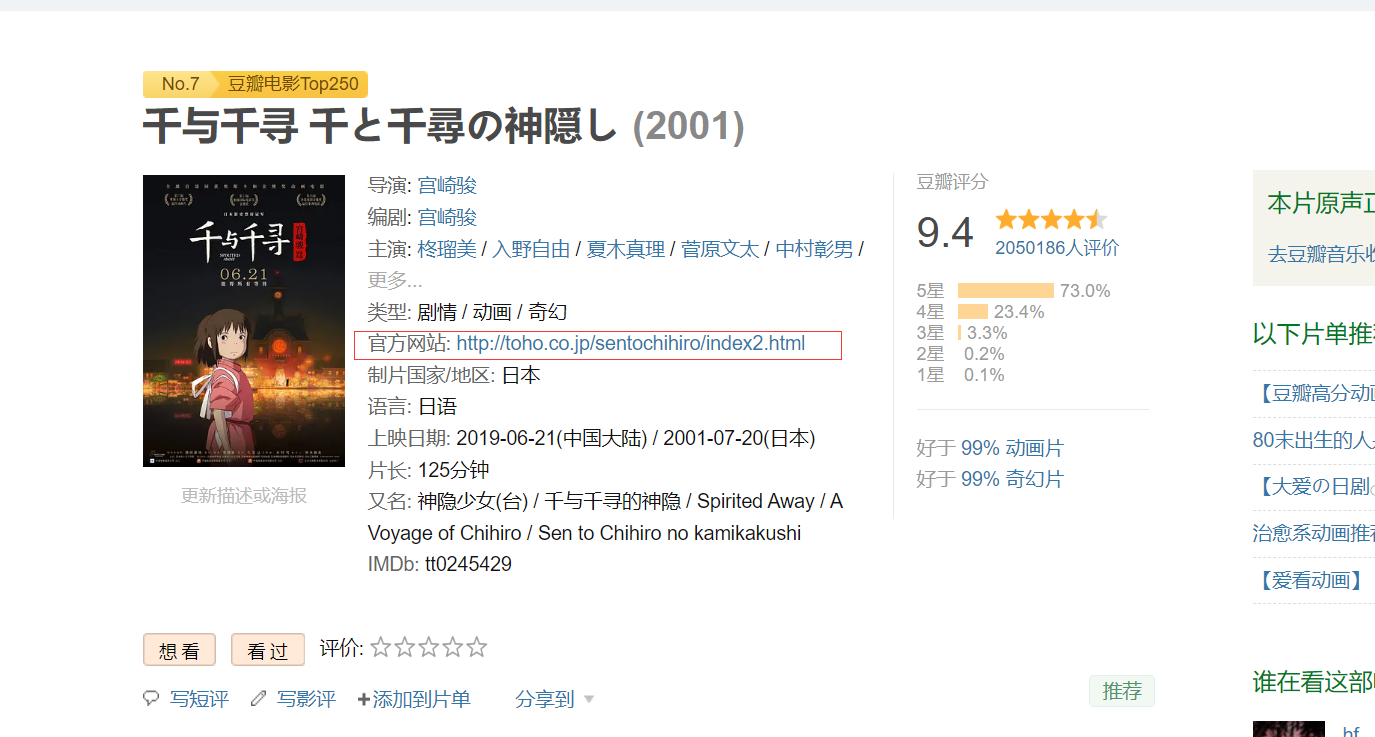
清洗和预处理 有的电影子页面的索引项不同,比如7.千与千寻中出现了官方网站,导致数据出现错位。
head=['rank' ,'film_name' ,'director' ,'scriptwriter' ,'actor' ,'filmtype' ,'area' ,'language' ,'initialReleaseDate' ,'runtime' ,'rating_num' ,'stars5_rating_per' ,'rating_people' ] for i in range (len (page_url)): href=page_url[i] time.sleep(random.randint(2 ,7 )) r = requests.get(href,headers=headers) r.encoding = 'utf-8' child_page=BeautifulSoup(r.text,'html.parser' ) rank = child_page.find(attrs={'class' : 'top250-no' }).text.split('.' )[1 ] film_name = child_page.find(attrs={'property' : 'v:itemreviewed' }).text.split(' ' )[0 ] director = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[1 ].split(':' )[1 ].split('/' ) scriptwriter = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[2 ].split(':' )[1 ].split('/' ) actor = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[3 ].split(':' )[1 ].split('/' ) filmtype = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[4 ].split(':' )[1 ].split('/' ) if child_page.find(attrs={'id' : 'info' }).text.split('\n' )[5 ].split(':' )[0 ] == '官方网站' : area = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[6 ].split(':' )[1 ].split('/' ) language = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[7 ].split(':' )[1 ].split('/' ) initialReleaseDate = min (child_page.find(attrs={'id' : 'info' }).text.split('\n' )[8 ].split(':' )[1 ].split('/' )).split('(' )[0 ] elif rank == "216" : scriptwriter = '无' actor = '无' filmtype = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[2 ].split(':' )[1 ].split('/' ) area = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[3 ].split(':' )[1 ].split('/' ) language = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[4 ].split(':' )[1 ].split('/' ) initialReleaseDate = min (child_page.find(attrs={'id' : 'info' }).text.split('\n' )[5 ].split(':' )[1 ].split('/' )).split('(' )[0 ] else : area = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[5 ].split(':' )[1 ].split('/' ) language = child_page.find(attrs={'id' : 'info' }).text.split('\n' )[6 ].split(':' )[1 ].split('/' ) initialReleaseDate = min (child_page.find(attrs={'id' : 'info' }).text.split('\n' )[7 ].split(':' )[1 ].split('/' )).split('(' )[0 ] runtime = child_page.find(attrs={'property' : 'v:runtime' }).text rating_num = child_page.find(attrs={'property' : 'v:average' }).text stars5_rating_per = child_page.find(attrs={'class' : 'rating_per' }).text rating_people = child_page.find(attrs={'property' : 'v:votes' }).text film_info=[rank,film_name,director,scriptwriter,actor,filmtype,area,language,initialReleaseDate,runtime,rating_num,stars5_rating_per,rating_people] df = pd.DataFrame([film_info]) current_path = os.path.dirname('__file__' ) if film_info[0 ] == '1' : df.to_csv(current_path+'douban_top250_test.csv' , mode='a' , header=head, index=None , encoding="gbk" ) print (f"top{film_info[0 ]} 爬取完成" ) else : df.to_csv(current_path+'douban_top250_test.csv' , mode='a' , header=False , index=None , encoding= "gbk" ) print (f"top{film_info[0 ]} 爬取完成" )
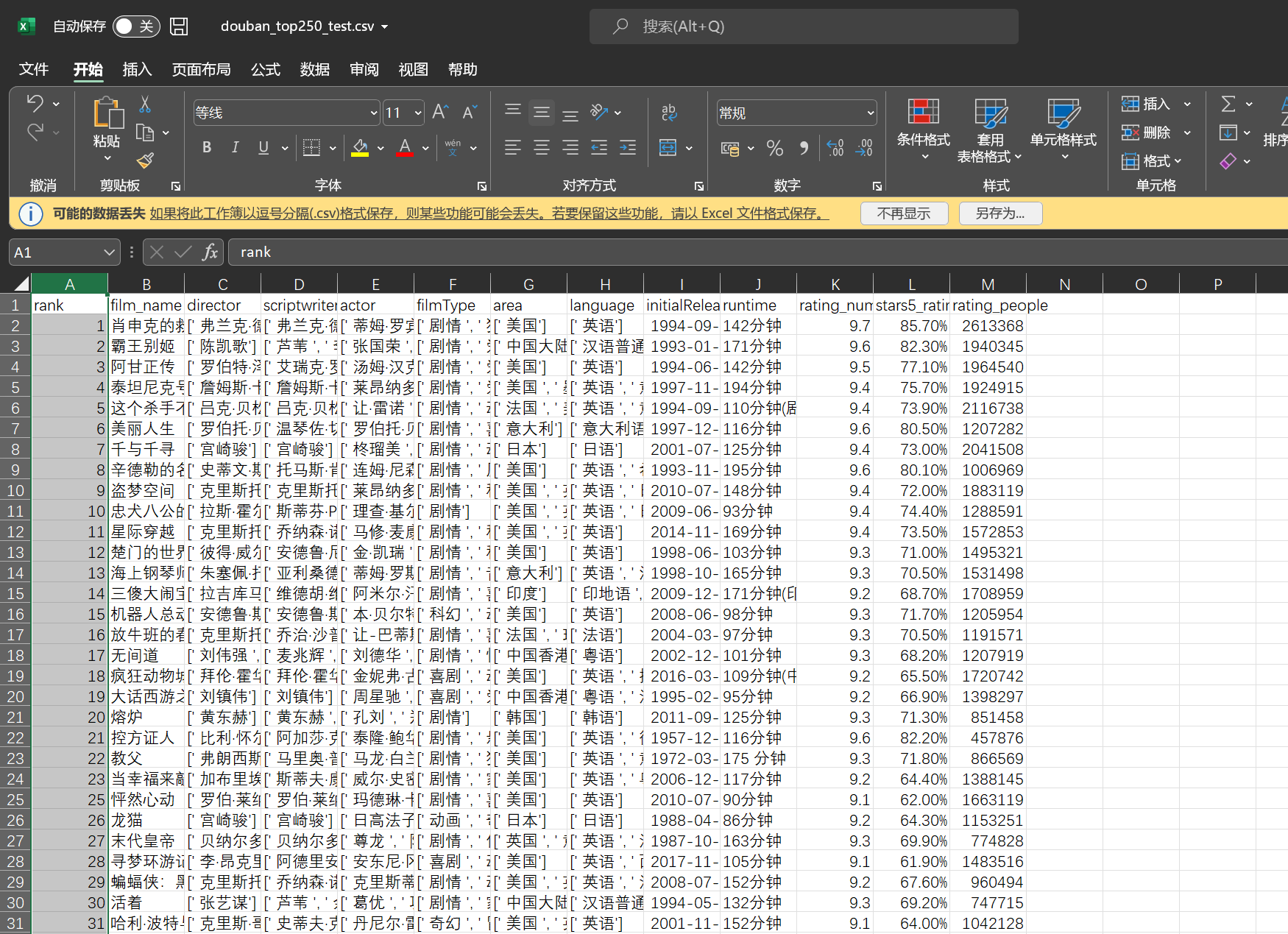
加入线程池加快爬取速度 if __name__ == '__main__' : for i in range (10 ): one_page(f"https://movie.douban.com/top250?start={i * 25 } &filter=" ) time.sleep(random.randint(1 , 2 )) print ("url提取完毕!" ) with ThreadPoolExecutor(50 ) as t: for j in range (len (page_url)): childUrl = page_url[j] t.submit(child, childUrl) head = ['rank' , 'film_name' , 'director' , 'scriptwriter' , 'actor' , 'filmType' , 'area' , 'language' , 'initialReleaseDate' , 'runtime' , 'rating_num' , 'stars5_rating_per' , 'rating_people' ] data = pd.read_csv(r'douban_top250_test.csv' , header=None , names=head, encoding="gbk" ) data.to_csv('douban_top250_test.csv' , index=False , encoding="gbk" ) print ("爬取完毕!" )
效果:
效果展示
特定数据的处理结果:



 QQ
QQ wechat
wechat alipay
alipay



